




¿Por qué los gobiernos y las ciudades deberían usar mejor sus datos?


Artículo publicado por BID, de Pablo Cerdeira. Ver artículo original aquí.
En los negocios “Lo que no se mide, no se puede mejorar”. Esta línea de pensamiento aplica también para las ciudades; dónde el crecimiento de dispositivos conectados al espacio físico incrementa la cantidad y calidad de la data recolectada: el 90% de la información disponible actualmente fue recolectada en el 2014 [1], y esto tendrá un crecimiento exponencial cuando la tecnología sea más accesible y a menos costosa. Presentando una oportunidad valiosa de uso de datos para la toma de decisiones y la mejora en la eficacia de los servicios en las ciudades.
El proyecto “Big Data para el Desarrollo Urbano Sostenible” [2] del BID, en materia de Bien Público Regional, incluye cinco ciudades de América Latina (São Paulo, Montevideo, Quito, Miraflores y Xalapa) y pretende intercambiar experiencias y desarrollar nuevos proyectos basados en datos para el diseño de políticas públicas. El objetivo de este proyecto, presentado en The SmartCity Expo World Congress en Barcelona en 2018, es el de romper la barrera natural que se forma entre electores y electos después de los períodos electorales, a través de datos e informaciones anónimas, al centro de las decisiones públicas. Para ello, el proyecto prevée que los datos de las centrales de atención, de las aplicaciones desarrolladas por las alcaldías e incluso del sector privado, como Waze, se utilicen para que las decisiones políticas tengan siempre fundamentos científicos y sociales actualizados, como ocurre en el período de elecciones.
Uno de los primeros ejemplos, en desarrollo, es un modelo que utiliza los datos de huecos en las vías reportados por los ciudadanos para crear una escala de prioridad entre ellos y medir los costos estimados involucrados. Lo que pudimos percibir es que, como sucede con muchas distribuciones de grandes números, en especial en las ciudades, se refleja un principio de Pareto. Es decir, cerca del 80% de los reclamos están concentrados en apenas el 20% del territorio. Esto puede ser muy importante para la toma de decisiones de los administradores públicos. El gráfico a continuación (por João Carabetta) nos muestra que, si el administrador público quiere atender la demanda de la población, debería comenzar por los lugares con mayor número de reclamos. Si el administrador invierte sólo el 20% del total de recursos necesarios para corregir todos los problemas en el asfalto en los lugares de alta concentración de reclamos, estaría atendiendo a la mayoría (casi el 80%) de los ciudadanos.
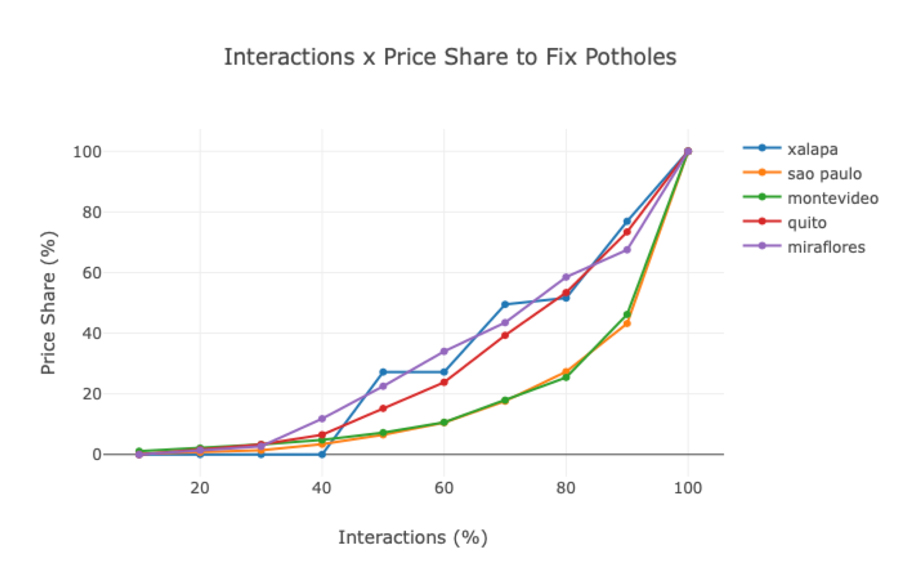
Interacciones x precio compartido para arreglar baches.
El uso de datos sacados de las redes sociales y producidos por la sociedad, como lo son Twitter, Waze, Facebook, etc., es nuestro primer desafío. Para hacer uso de esta información y compararla con otros datos, es necesario validar que tan representativa puede ser. Varios estudios han demostrado que los ciudadanos no siempre tienen el mismo acceso a la data que se produce. Esto lo podemos ver en el ejemplo a continuación dónde se compara el análisis de la distribución de ingresos con la población total al del análisis reflejado de datos sacados de las redes sociales [3].
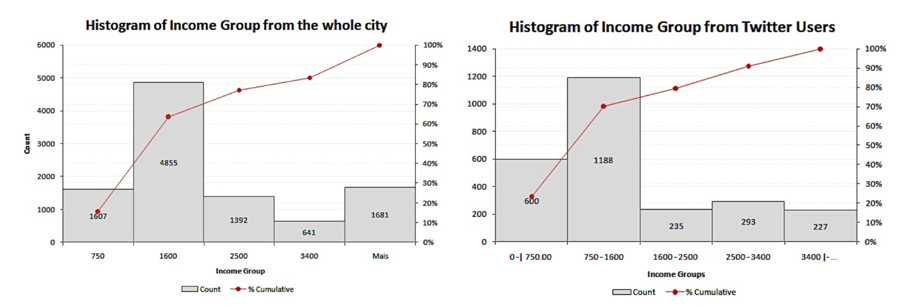
Distribución de la población y distribución de los usuarios de redes sociales en Río de Janeiro
El segundo desafío es que los datos del Big Data no se producen pensando en sus usos como fuente de investigación, y por eso, en casi todos los casos, demandan un gran trabajo de estructuración, limpieza y tratamiento, con el uso de algoritmos que pueden ser complejos, para atender los objetivos del administrador público.
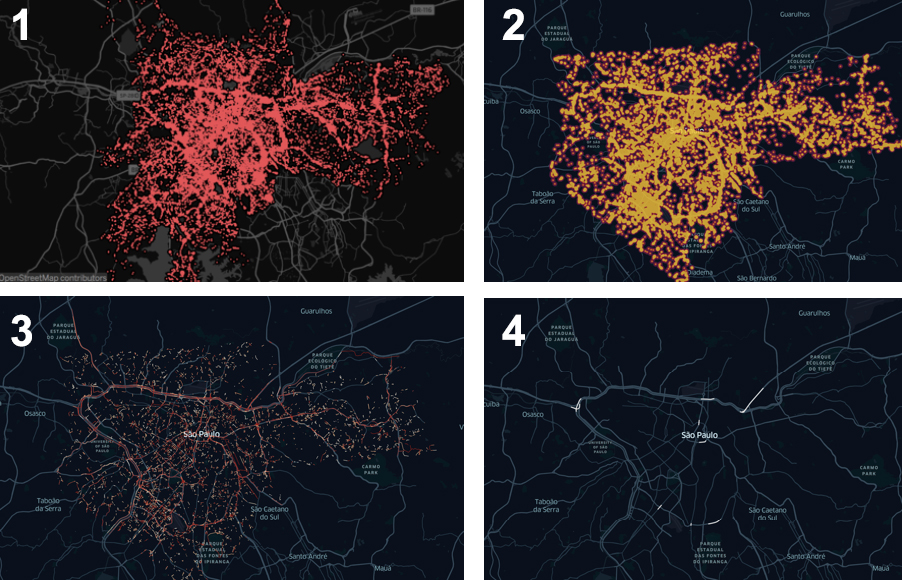
Trabajo sobre datos brutos hasta que se consideren datos útiles. Figura 01: datos brutos de agujeros en São Paulo Figura 02: Datos agregados, pero aún no superpuestos a las vías Figura 03: datos ya agregados y calculados sobre las vías Figura 04: Selección del top 10% de las vías más reclamadas.
El tercer reto, donde nos encontramos actualmente, es hacer la validación de estos datos de manera local. El objetivo es validar los datos generados por los ciudadanos y sus efectos reales en las ciudades. Creemos que con ello podremos desarrollar modelos que se apliquen a todas las ciudades de América Latina y el Caribe, permitiendo a los administradores decidir sobre la base de la información que sus propios ciudadanos envían, aunque no se utilizan.
Este es sólo un ejemplo de lo que se pretende desarrollar en el marco del proyecto “Big Data para el Desarrollo Urbano Sostenible”. En el futuro, esperamos utilizar métricas adicionales para evaluar la calidad de los servicios prestados, como por ejemplo el tiempo que toma recibir la atención adecuada a un problema y el tiempo que toma para solucionarlo; e incluso el número de personas afectadas. Con la identificación de nuevas fuentes de datos y nuevas formas de aplicación para la decisión pública, esperamos ayudar a ahorrar recursos, reducir el impacto negativo en el medio ambiente y contribuir a la creación de nuevas formas de administración pública que consideren a los ciudadanos y sus manifestaciones para la toma de decisiones que atiendan mejor a la sociedad.
Editores BID: Este artículo también se benefició significativamente de los aportes técnicos y el apoyo proporcionado por Mauricio Bouskela, Marcelo Facchina y Hallel Elnir.
[1] http://publicadministration.un.org/egovkb/en-us/reports/un-e-government-survey-2016 [2] http://www.iadb.org/en/sector/trade/regional-public-goods/home [3] Netto, v., Pinheiro, M., Meirelles, J., and Leite, H. (2015). Digital Footprints in the cityscape: finding networks of segregation through Big Data. At http://www.researchgate.net/publication/272408306_Digital_footprints_in_the_cityscape_Finding_networks_of_segregation_through_Big_DataPablo Cerdeira
Pablo Cerdeira is the Head of the Center for Technology and Society in FGV and responsible for the project of use of large volumes of data for the public administration of the City of Rio de Janeiro, at Big Data: PENSA – Ideas Room. He was the former advisor to the National Council of Justice, professor at the Getúlio Vargas Foundation – RJ, and undersecretary for Consumer Protection and Chief Data Officer of the City of Rio. He has experience in law, with emphasis on law and technology, working mainly in the areas of free software, law, Linux, information technology and databases. In the intersection between law, public administration, programming and data science, he was the creator of the Supreme Numbers Project of Rio Law School of the Getúlio Vargas Foundation – FGV.










{kind=link}